
Data as Placebo
Who cares about the truth anyway?
Introduction
It has become popular to focus on data for making decisions. Uber writes that “data is crucial for our products”. Meta writes about making “data-driven decisions”. Google famously uses data and runs experiments on their own employees as part of HR. This isn’t a new phenomenon, it goes back far enough that by 2010 there was already a backlash against being “too data-driven”, and instead a suggestion to be “data informed”. But rather than discuss the limitations of this approach (which I could very well do), I will instead focus on the times that we think we are using data but we really aren’t, hence data as placebo.
The word “placebo” comes from the Latin “to please” and was used because of the idea that participants in an experiment might simply be trying to please the experimenter, and hence report positive results. For example, you may feel bad telling the experimenter that your headache didn’t get better after they gave you some questionable remedy so you lie and say it did. This may even be on a subconscious level, such that you don’t realize you are lying. Hence you may actually think it did get better, which is easy to be wrong about with a subjective experience (we might even say that in such a case it did get better, hence the placebo effect).
We see a similar thing when using data. It is often that there are some subjectively determined outcomes that are desirable, and we look at data to confirm them, rather than actually using it to guide any decisions. The truly nefarious aspect of this is that, much like in medicine, this may occur subconsciously such that everyone is truly and honestly sure that they did indeed use data to determine their best course, when in reality that is not at all what happened. In this article I’ll explore some ways this can happen.
Novelty Effect
A novelty effect is a result in an experiment that comes from the novelty of a change. For example, introducing a new color scheme to your website might cause people to react (either positively or negatively) merely because of the change. This effect will diminish once people are used to the color scheme change, and have gotten used to it. At that point there will likely be a much smaller effect compared to the baseline.
The error made with novelty effects is to confuse the initial effect with the final result. This could come from running an experiment for only a short period, or averaging the data over the whole period instead of looking for trends.There might be a lot of excitement at initially very positive experimental results so that no one is incentivized to look too closely if they persist in the longer term.
Let’s consider a specific example that I witnessed. In systems such as search, ads, and recommendations, a common metric is “click-through rate” or CTR. This measures what fraction of the items shown to the viewer were clicked on. Typically higher is better, for example if the viewer clicked on an ad that means the ad was probably better than one they did not click on. Let’s say the CEO of your company proposes a new idea for recommending products on your site. You will show them with much larger photos in a more prominent location. Like a good data scientist, you run a proper A/B test with a control group, comparing the new method with the old. And perhaps the true results of the experiment look like this:
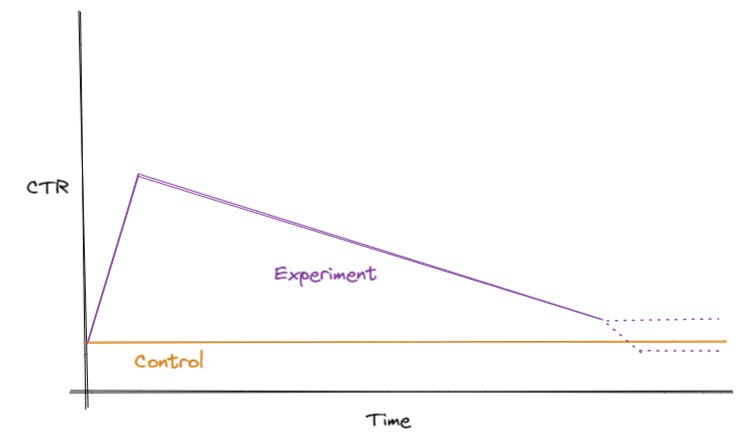
Initially users are interested in the new recommendations placed much more prominently. Many more of them click on them, presumably interested. But over time as everyone gets used to this placement, they go back to ignoring them most of the time, as they did with the prior placement. Here I’ve drawn two dashed lines showing possible situations. It could be that the end state still results in superior results, or it could be that it’s actually worse. If we keep running the experiment we would find out, but instead we decide to stop it, since it’s clearly a rousing success. We look at the data pooled over the whole period and find that CTR went up +100% compared to the control, which passes any test of statistical significance you’d like to use. So the change is shipped and the CEO is pleased.
It’s not too hard to avoid these issues by running an experiment longer and discarding data the initial time period. But this may be unappealing in a “move fast” world that wants quick results. If an experiment looks promising why not apply the gains to the entire business right away? It can be very difficult to fight against that. And at the same time, if you do discard the initial data, this can introduce its own source of bias.
Equilibrium Effects
Often, in a typical experiment only a small % of the total population will get some test condition. For example, say you want to test if a new sales promotion increases your sales. You might send out a promo code to 1% of your users and see how many buy something, compared to a control group. This type of experiment would also have novelty effect issues (if you have promos weekly that won’t be as effective as once a year), but let’s say you are planning a one-time campaign. You do the test and everything looks great, the 1% test group had a 50% increase in purchases compared to the control. This can’t possibly be another data placebo, can it?
Enter the complicated world of equilibrium effects. These refer to a situation in which there is an equilibrium, and a change introduced to the system disrupts it. The equilibrium then responds against the disruption, reducing the impact of the change. For example, let’s say a typical person spends $100/month on cookies at the local store. But one month, one person gets an extra bonus at work and so buys twice the usual amount–$200. This is just one person, so nothing really happens. But let’s say instead everyone in town gets an extra bonus (perhaps a government rebate). Suddenly everyone wants to buy $200 of cookies. The store doesn’t have enough cookies to meet that demand, and raises the price to double. Everyone ends up paying $200 for the same amount of cookies they would have gotten for $100. Essentially the bonus went to the store instead of the people.
This is a simplistic example, and in practice equilibrium effects can be much more complex and far-ranging. Let’s go back to our sales promotion example. We could imagine several equilibrium effects that would come up if we scale it to the whole population of users:
Perhaps people are merely shifting their spending forward in time. They were going to spend $100 at our store anyway, but the promotion made them spend it sooner. If we consider earnings for the whole year, the promotion might actually cost us money, since we’ll have given them a discount for things they would have bought later anyway.
Perhaps there is indeed an increase in purchases, but this affects supply (some popular items go out of stock), reduces delivery speed (too many orders at once), or has other negative quality consequences. These result in other customers becoming upset and placing fewer orders, reducing some of the gains.
Perhaps the purchaser is interested in the promotion because it’s special. If everyone gets the promo code then it’s no longer as exciting to be using it. It might seem like it’s an everyday occurrence and not cause any new purchases to be made. Conversely anyone that doesn’t get the promo might be hesitant to buy because they might expect to get a discount in the future.
Equilibrium effects can be almost impossible to accurately predict, because the world is so complex. They do encourage us to think about the potential effects and what happens when a change scales from acting on a small percentage to the whole population. And in practice equilibrium effects won’t usually eliminate all of a gain, merely dampen it somewhat.
Other Data Placebos
There are many other causes of data placebos. Rather than make this article overly long I’ll give a quick summary of them.
Too small sample size. You only tested on 5 people and they all liked the change. This could be just due to chance.
Biased sample. You only tested on volunteers and they responded positively. Tests need to be done on a randomly selected group.
External factors. You happened to run the test during a major holiday. The results may not apply the rest of the year.
Bugs. The code for the test had a logging issue so accidentally coded the experimental group as more successful than it really was. By the time you find the issue the decision to ship the change has already been made.
Missing metrics. You tested your change on metrics A, B, and C and all look good. But you forgot to check D and E, which went down a lot.
Too many metrics. The converse of #5. Wary of missing metrics, you tested on all 100 metrics your company tracks. Due to chance, 5 of them passed statistical significance tests for improvement. So you ship the change.
Design is not faithful. The experiment was done with an initial design. The results are good but you decide to ship with some design changes based on feedback. These changes are not re-tested.
Implementation is not faithful. For the test you mock part of the implementation, since you don’t want to spend too much time on it before you actually ship. But when actually shipping, this changes the logic so much that the results don’t carry forward.
Cost doesn’t scale. A new feature produces very positive results. When doing the test you only needed a small amount of extra resources that fit within your existing server budget. But when scaling to everyone you realize you will need $x in server costs, which cancel out any gains.
Non-linearity of changes. You tested two changes, A and B, separately. Each one was good in isolation. But when you ship them both, they conflict and the end result is worse.
There are techniques to avoid all of these but it’s very difficult (and most likely unrealistic) to avoid all of them. So some degree of data placebo will inevitably slip in. The key is to identify what kind of decision you are dealing with. If it’s something you will probably do anyway, don’t waste everyone’s time with experiments. Simply ship the change and monitor key metrics afterwards. You can always roll back if the metrics are sharply negative. On the other hand if you honestly don’t know which option to go with and want the real truth from data, be very careful when designing and analyzing your experiment. Question any result that looks too good to be true (it pretty much always is). There’s no way changing the color of a button increases conversions by 50%. Indeed it’s uncommon to have changes that are significantly positive, and these should be looked into most of all. With that you have at least some chance of avoiding the data placebo.
Coding interviews are a fantastic waste of time, no matter how they are done. Any demonstration of actual, real coding skill takes thousands of lines of code, and days of effort.
Our job is not writing code, our job is to think. If our job was as trivial as for loops and variable assignments, it would have been automated a long time ago. Reducing our job to just lines of code is as completely asinine as reducing a recruiter's job to clicking in LinkedIn.
Developers suck at interviewing for three main reasons:
1. They don't give a crap - hiring is as irrelevant to our job as paying the bills, running the company, managing a project, or answering the phone.
2. Developers have no idea how to assess themselves, never mind another person. They spend zero time assessing others, because that's a managers job.
3. Developers are arrogant - in interviews, they are stupid enough to believe a mans' career can be reduced to a 1 or 0, good enough to be here or too stupid to be here, and arrogant enough to believe they actually know how to make this reduction.
Any standardized code test is invariably designed to highlight the skills of the guy who wrote it, which has screw all to do with the skills of the candidate. At the same time, I find developer interviewers come in two flavours - passers and failers (the majority are the latter). A passer just runs the unit test of a code test and asks some dumb questions a two year old with a cell phone can answer, they'll pass anyone who wrote a working solution and correctly answered a few "what are the ingredients of orange juice in alphabetical order" questions. A failer will barf at a code test that not's the way he would write it, or decide correctly answering orange juice ingredient questions indicates the candidate is an idiot.
All of this is why managers should do interviews, not developers. They actually give a damn to be there, they now how to assess people, they ask intelligent questions, they come to intelligent conclusions. Strangely, I never got ghosted as too stupid to be here when interviewed by managers.
If you a/b test wouldn’t the external factors mostly cancel out